
让我们一窥 AlphaGo‘让天下三子’的棋力及其背后的技术 文/杜夏德 参与:李泽南、吴攀 来源:机器之心 5 月 23 日,乌镇围棋峰会第一场人机大战以柯洁落败而结束,DeepMind 和谷歌在今天的人工智能高峰论坛中详细回顾了昨天的比赛,并解读了 AlphaGo 背后的强大实力。 第一天比赛结束,DeepMind 创始人 Hassabis 表示,比赛进入了数子阶段,AlphaGo 的优势很小,柯洁完成了一场伟大的比赛。竭尽全力的柯洁表示,此次大赛之后不但不会再与机器交战,也不会利用机器来练习,他‘更喜欢与人类棋手下棋,这样自己还有赢的可能。’ 比赛之后,DeepMind 在官方网站上发布了一篇对这场比赛的分析解读,机器之心对这篇文章的内容进行了编译介绍。同时,我们还整合了机器之心前方记者发回的一线报道,让我们可以一窥 AlphaGo‘让天下三子’的棋力及其背后的技术。 第一局比赛官方回顾  柯洁与 AlphaGo 在围棋峰会上的第一场比赛跌宕起伏,黑棋和白棋都展现了细致入微的精细布局。经过多次局部交锋与创新的变化,AlphaGo 执白坚持到了最后,以 0.5 点(1/4 子)的微小优势获胜。 在开局阶段,柯洁使用了大胆的策略率先发起了攻势,他采用了以往 AlphaGo 最喜欢的举动——点三三。这种策略在 20 世纪 30 年代由围棋界的传奇吴清源与木谷实引入棋坛,并在棋坛流行多年,但在当代棋坛销声匿迹。然而,随着 AlphaGo 的出现,最近柯洁等顶级棋手已经开始尝试在正式比赛中将这一方法复兴了。在柯洁走出点三三后,AlphaGo 以它最喜欢的二间拆应对,柯洁向前延伸,完成了侵入。此前,随着 AlphaGo 在以 Master 名义进行 60 盘网上对局的比赛中,这样的变化正逐渐流行起来。 
柯洁和 Demis Hassabis 在比赛之前握手 跟着就是一个罕见的三三打入定式,然后 AlphaGo 落下了非常新颖的一子:它没有直接以扭的方式打吃或使用常见的飞,而是在第 24 手使用了大飞扩展了范围。樊麾相信 AlphaGo 此举体现了它自己的哲学:‘AlphaGo 的方式并不是在这里那里争夺棋盘局部的空间,而是把每颗棋子都放在对大局最有意义的位置上。这是真正的围棋理论:并不是“我想要得到什么”,而是“我该怎样让每颗棋子都发挥出其最大的潜力”。’ 之后,两位棋手在左上角进行了一场激动人心的交换,柯洁在这个过程中表现出色。放弃托角而取得边,黑棋在一场交换中吃掉了四颗白子,而 AlphaGo 评估认为这对双方来说都是理想的结果。柯洁真不愧是世界第一!通过在第 49 手使用的方法,黑棋在下盘威胁到了白棋的厚势,但白棋在第 50 手和 54 手时通过刺和断转变了方向。这些走法的目标并不是直接的跟随,而是在精妙地最大化其在这一区域的实力和未来的主动权。尽管 AlphaGo 更偏爱单关跳来强化其中心实力,柯洁在第 51 手对四颗白子进行了包围,维持了对局部的控制。在第 55 手,一着聪明的试应手让黑棋通过左底部边角来交换更下面的边,柯洁的这一步选择为棋局的未来进展设定了方向。在黑棋在边角存活下来之后,却给了白棋一道外围的铜墙铁壁,柯洁果断地放弃了他在更下面边的棋子,以在上部分获得更强的优势和主动权。 随后,在所占的实地落后的情况下,柯洁被迫充分利用上边,从而在第 97 手下出了雄心勃勃的大跳(这或许是胜负手)。AlphaGo 在第 98 手的反应又迫使柯洁在第 99 手截断这单颗白棋,这一决定性的变化开启了这局比赛的最后一次大范围交换。在收官阶段,柯洁奋力追赶,而 AlphaGo 则保持适当但安全的领先,最终以四分之一子的优势获胜。 DeepMind 希望我们在这场比赛中看到的创新能够成为围棋更多创新的开始,并期待全世界的棋手们都能分析这些下法,并在未来的对弈中尝试它们。 ‘让天下三子’的棋力和技术 比赛之后,David Silver、谷歌大脑负责人 Jeff Dean 等人在乌镇围棋峰会现场对 AlphaGo 背后的技术进行了解读,以下是机器之心对相关内容的整理解读。
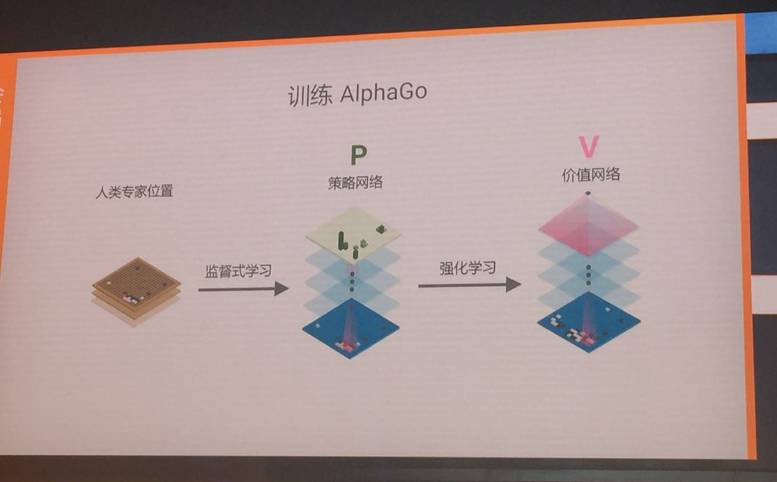 机器之心已经多次报道过了AlphaGo的基础技术,可参阅机器之心昨天的报道《柯洁 1/4 子惜败,机器之心独家对话AlphaGo开发者导师 Martin Müller》。AlphaGo 结合了监督学习与强化学习的优势。通过训练形成一个策略网络,将棋盘上的局势作为输入信息,并对有所可行的落子位置形成一个概率分布。然后,训练一个价值网络对自我对弈进行预测,以-1(对手的绝对胜利)到 1(AlphaGo 的绝对胜利)的标准,预测所有可行落子位置的结果。 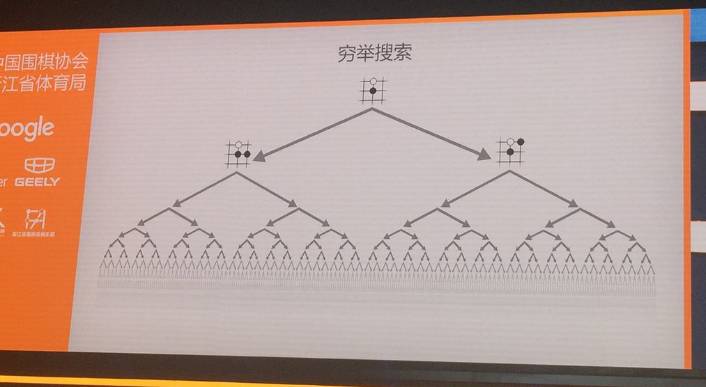 围棋的分支系数非常大:每一颗棋子可能的走法数量超过了整个宇宙的原子数量,而且不像国际象棋,它无法用穷举搜索的方法来得到结果。  为了减少搜索的宽度,AlphaGo 会根据策略网络(policy network)探索哪个位置同时具备高潜在价值和高可能性,进而决定最佳落子位置。  而为了减少搜索的深度,AlphaGo 使用了价值网络来进行评估。虽然 AlphaGo 的价值网络不能准确地计算出影响的数值,但它的价值网络能够在一定深度上一次性考虑棋盘上的所有棋子,以微妙和精确的方式做出判断。正是这样的能力让 AlphaGo 把自己在局部的优势转化为整个比赛的胜势。 
AlphaGo 将这两种网络整合进基于概率的蒙特卡罗树搜索(MCTS)中,实现了它真正的优势。
 现在的 AlphaGo 使用的是去年的硬件(TPU 第一代),系统共用到 4 个 TPU ,相比去年与李世乭对弈时需要的计算能力大幅缩小,而因为算法效率的提高,围棋水平却增强了。 一间 64 台 TPU 的舱中,有 1/8 用于训练的一个机器翻译模型,也就是说有 8 个 TPU 训练机器翻译模型。谷歌软件工程师陈智峰告诉机器之心记者,在他们所做的模型训练测试中,使用 8 个 TPU 能让原先的训练时间从 24 小时缩短到一个下午。谷歌的 TPU 舱还在建立中,在问及谷歌目前有多少个这样的 TPU 舱时,谷歌方面还不愿透露。 
在基本方法的基础上,AlphaGo Master 有了进一步的提升。
 其可以复盘前面的棋局,预测走到哪一步就可以赢,每一步都预测未来的赢家。原版的网络有 12 层,而 Master 有 40 层。 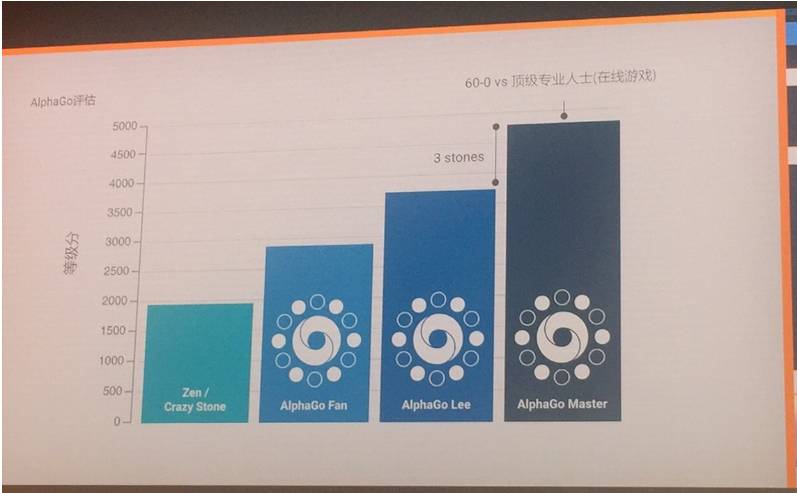 在棋力评估上,与樊麾对弈的 AlphaGo 版本比 Zen/Crazy Stone 有四子的优势,而与李世石对弈的 AlphaGo 版本比与樊麾对弈的 AlphaGo 版本又有三子的优势,而现在最新的 AlphaGo 版本又新提升了三子的优势。 深度强化学习不仅可以用来下围棋,而且还可以进行像素学习,学习 3D 虚拟游戏,可以自己学会在 3D 环境中学习导航。  另外据Jeff Dean介绍,谷歌建有TPU舱,一个TPU舱里面包含64台二代TPU,能进行每秒11.5万亿次浮点运算,4倍快于市面上最好的32台GPU。 
各方对本局比赛的点评 在 5 月 23 日的比赛过后,参赛两方和各路围棋职业选手围绕棋局和技术的角度对这场对决进行了解读。 柯洁:我很早就知道自己要输 1/4 子,AlphaGo 每步棋都是匀速,在最后单官阶段也是如此,所以我就有时间点目,看清自己输 1/4 子,所以只好苦笑。 如果要我自己点评,AlphaGo 确实下得太精彩,很多地方都值得我们去学习、探讨,思想和棋的理念,改变我们对棋的最初的看法,没有什么棋是不可以下的,可以大胆去创新,开拓自己的思维,去自由的下一盘棋。今天我也是大胆去开拓自己的思维,在我印象中,AlphaGo 非常贪恋实地,开局点三三等等。所以今天我也一直贯彻先捞后洗的战术,先把实地钞票捞到手,但在角部还是被他掏到实地,打破了我的战术,一下子就进入他的步调了。感觉 AlphaGo 和去年判若两人,当时觉得他的棋很接近人,现在感觉越来越像围棋上帝。我希望尽全力去拼每一盘棋。很感谢有 AlphaGo 这样的对手,感谢 DeepMind 团队给我机会去下这三盘棋,也希望通过这次比赛让大家了解围棋这个好项目,给大家带来快乐。 AlphaGo 其实已给我们展现了很多精彩的实战,弱点暂时还没有看到。我觉得以前他还是有,但现在对棋的理解和判断远胜于我们,所以想赢只好通过找 BUG,但真的很难。不过对自己永远要有信心。之前我发微博说,这可能是我与人工智能最后三盘棋,现在就只剩两盘棋了,这可能是我活到现在最难得的机会,我会尽全力去珍惜这次机会。 我做这个决定已经考虑很久,因为我觉得 AI 进步速度太快了,每一次都是巨大进步,我觉得以后可能会变得更加完美,人与他的差距不是靠自身的努力可以去弥补的。我还是想和人类下棋,因为到未来,我们与 AlphaGo 的差距可能越来越大,人和人的差距可能越来越小。我对人的胜率还可以。这次峰会是我与人工智能的最后 3 盘棋,当然也不会在网上与人工智能练棋。如果人类比赛中出现 AI,我虽然不愿意但也不是我能决定的,我觉得我也可能会输。我其实对今天的表现有点不满,觉得能做的更好。但这次是最后一次较量,希望不留遗憾,下出好棋,让 AlphaGo 主机更发烫一点也好。 Michael Redmond(目前唯一的非东亚裔围棋九段选手):柯洁从今年 1 月份 Master 的一系列比赛中获得了灵感,在他的布局中加入了一些新变化。他在今天的比赛中使用了和 AlphaGo 类似的低位打入策略,这是以前闻所未闻的举动。尽管这是一个我们难以理解的策略,但过去一个月职业棋手们一直在对它做出自己的解读。 此外,在 5 月 23 日比赛结束后的新闻发布会上,AlphaGo 团队的 David Silver 透露了新一代 AlphaGo 是年初 Master 的升级版,并提到一些细节:新的 AlphaGo 程序运行在单个谷歌云服务器上,由 TPU 芯片进行计算处理。算法上也进行了革新,它所需的计算能力仅需与李世乭对战时的 10%,自我对弈能力更强。去年,AlphaGo 的模型中有 12 层神经网络,而在以 Master 名义出战时,深度已有 40 层。 在被问及 AlphaGo 是否控制了本局比赛的胜率时,Silver 解释道,扩大每一步棋胜率是 AlphaGo 的探索的一个方向。如果只是为了取得最终的胜利,每一步它都会选择走风险很小的棋。 Demis Hassabis(DeepMind 创始人和首席执行官):伟大的比赛!向柯洁致以敬意,他将 AlphaGo 推向了自己的极限。AlphaGo 仍需要和人类对弈,它需要先学习人类棋谱,随后开始通过自我对局来进步提高,所以 AlphaGo 是依靠人类棋谱数据和此前版本来进一步提升。仅通过自身对决可能发现不了缺陷,和顶尖棋手对决才能提高。我们希望通过完善 AlphaGo,在其他领域为人类服务。我们在《自然》上发表了论文,本周之后我们会公布更多细节和计划,众所周知目前也有很多强大人工智能软件,我们也会在今后公开 AlphaGo 更多技术细节,使其他实验室或团队能够建造自己的 AlphaGo。(创事记)
| 







 发表于 2017-5-25 15:56:38
发表于 2017-5-25 15:56:38

 收藏
收藏